Fueling the AI Revolution: Why the Billion-Dollar Race for Labeled Data Shapes Every Breakthrough
June 18, 2025 • 6 min read

A quick confession before we dive in …
When I accepted my role at iMerit, I thought I had a solid handle on how machine-learning pipelines worked. Models, GPUs, fancy algorithms, sure. But the idea that an entire market existed just to “label data” never crossed my mind. Then week one arrived: I heard about teams of expert annotators drawing bounding boxes around street signs and doctors meticulously tagging CT scans.
That’s when it clicked, annotation isn’t a side quest; it’s the main road. Every Gen-AI milestone you read about, from ChatGPT’s witty banter to self-driving cars spotting pedestrians at dusk, starts with someone (often thousands of someones) labeling raw data so the model knows right from wrong.
I was surprised, then fascinated, and finally a little awestruck when I realized just how much money, talent, and strategy flow into this invisible layer of the AI stack. The deeper I went, the clearer it became: if compute is the engine, labeled data is the fuel, and fortunes rise or fall on its quality.
1. What is data labeling?
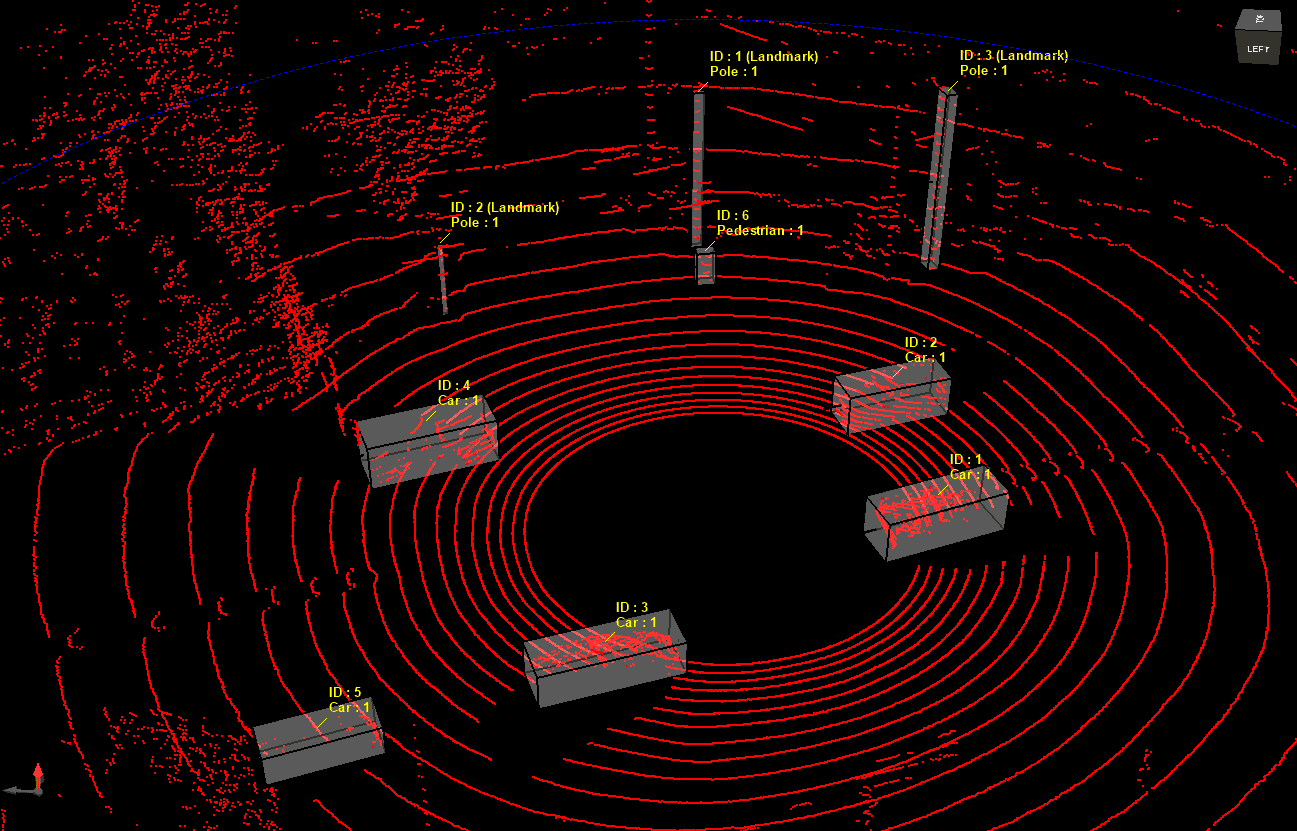
Data labeling (or annotation) is the process of adding structured, human-readable tags, classes, bounding boxes, sentiment scores, spans, and other relevant information to raw text, images, audio, or sensor data, enabling an algorithm to learn the mapping between inputs and outputs. It sits between data collection and model training in the ML lifecycle, and accounts for a significant share of project time and cost: multiple industry surveys still find 60-80 % of a data-science budget is consumed by finding, cleaning, and labeling data.
2. Why does it matter so much?
2.1. Accuracy & generalisation
Models trained on richly annotated, diverse datasets achieve higher accuracy and lower error bars. When MIT researchers manually fixed label errors in ImageNet, many top-performing models flipped places, proving they had “learned the mistakes.”
2.2. Safety & alignment
OpenAI’s ChatGPT, for example, transitions from a web-scraped pre-training to a supervised fine-tuning and finally to RLHF (Reinforcement Learning from Human Feedback). All three phases rely on expert-labeled demonstrations and preference pairs. The same approach underpins newer alignment efforts such as CriticGPT.
2.3. Compliance & trust
In high-stakes domains (AVs, medical imaging, defense) regulators increasingly demand audit trails that trace each prediction back to a labeled datum. The U.S. National Geospatial-Intelligence Agency’s forthcoming program alone will spend hundreds of millions of dollars on secure annotations.
3. A ballooning market
| Metric | 2024 | 2030/34 forecast | CAGR |
|---|---|---|---|
| Global data-labeling spend (Grand View) | US $3.8B | US $17.1B | 28% |
| Broader “solutions & services” (Fact MR) | US $12.7B | US $92.4B | 22% |
Recent deals demonstrate just how strategic labeling has become: Meta is negotiating a US$10–14B stake in Scale AI, instantly reshaping the data supply chain for rivals like Google and OpenAI.
4. Why companies spend (a lot)
Computing without data is useless; training curves plateau if examples are noisy or scarce; new frontier models need expert-curated reasoning traces, not just more tokens.
Cost of poor quality: A single mislabeled pedestrian in an AV dataset can propagate to millions of unsafe miles in simulation and road tests.
Human bottleneck: pixel-accurate semantic segmentation can cost $6.40 per image at Scale AI; fleets with millions of frames quickly surpass the million-dollar mark.
Competitive secrecy: annotation guidelines, ontologies, and evaluator pools have become trade secrets; Meta’s investment triggered an exodus of customers who no longer want to share data with a competitor.
Hidden labour, ethical risk: OpenAI’s toxicity filter relied on Kenyan contractors paid < $2/hour to read disturbing content, sparking debates on data-worker welfare.
5. Domain snapshots
5.1. Autonomous driving
Tesla employs hundreds of in-house labelers, yet still laid off a 200-person team in San Mateo in 2022 as it pivots to automation. Even so, “auto-labeling” pipelines still require humans in the loop to spot rare edge cases.
5.2. Natural-language assistants
ChatGPT, Claude, and Gemini each consume tens of thousands of expert-written conversation pairs. The labelers often hold graduate degrees and operate sophisticated rubric tools, driving unit costs far above the basic annotation costs.
5.3. Enterprise computer vision
Retailers tag shelf images; insurers mark hail-damaged areas; agritech firms pinpoint crop disease spots. Appen’s 2024 “State of AI” report notes that as use cases diversify, data accuracy has fallen by 9% since 2021, forcing companies to reinvest in re-labeling.
6. Challenges & emerging solutions
| Pain-point | What's Happening |
|---|---|
| Quality drift | Active-learning loops flag low-confidence samples for fresh labeling. |
| Scalability | Synthetic data (scene-graphs, simulation, diffusion-based augmentation) now complements human labels to cut cost. |
| Ethics & bias | Diverse annotator pools, differential-privacy on metadata, and wellbeing programs address bias and mental-health concerns. |
| Automation ceiling | Tools that auto-suggest labels can trim 30-50 % of manual effort but still rely on human verification for long-tail cases. |
7. Best practices for teams
Design the ontology first: mismatched class definitions can lead to expensive rework.
Instrument data quality metrics (inter-annotator agreement, Gold-set accuracy) should be evaluated early and monitored continuously.
Budget realistically: plan on annotation consuming at least a third of the total project budget for safety-critical systems.
Blend human and machine labeling: use auto-labelers to pre-annotate, then allocate human resources to validation and hard negatives.
Invest in labeler UX: intuitive tools, keyboard shortcuts, and clear rubrics raise throughput and morale.
8. Outlook
As foundation models push toward reasoning and multi-modal understanding, the bar for “ground-truth” data is rising from pixel grids and sentences to complete scene graphs, causal chains, and human preference hierarchies. Companies that build robust, ethical, and scalable labeling pipelines today will own the leverage in tomorrow’s AI economy.